0、 摘要
在Spring Boot工程中使用HanLP工具,按照平常的配置,将根路径配置为root=src/main/resources/HanLP/始终加载不成功,总是显示Caused by: java.lang.IllegalArgumentException: 核心词典src/main/resources/HanLP/data/dictionary/CoreNatureDictionary.txt加载失败
的错误,然而平时常规的maven工程中这么用是没有问题的。
经过查阅源码,最终发现HanLP提供了IO适配器来解析路径,默认的适配器用的是com.hankcs.hanlp.corpus.io.FileIOAdapter,是基于普通文件系统的,我们通过自己定制一个IO适配器,并在配置文件中配置指定适配器的类型,就可以正常读取resources下的data了,这样避免了使用绝对路径,本地运行和服务器运行都比较方便!
1、问题描述
按照常规Maven工程的方式配置hanlp的配置文件,如下所示:
1 | #本配置文件中的路径的根目录,根目录+其他路径=完整路径(支持相对路径,请参考:https://github.com/hankcs/HanLP/pull/254) |
可以正常解析配置文件并加载词典,并运行,但是迁移到SprintBoot工程之后,就会遇到如下错误:
1 | 2020-07-03 11:05:04.984 WARN 29664 --- [pool-1-thread-1] HanLP : 读取HanLP/data/dictionary/CoreNatureDictionary.txt.bin时发生异常java.io.FileNotFoundException: HanLP\data\dictionary\CoreNatureDictionary.txt.bin (系统找不到指定的路径。) |
2、将路径配置为绝对路径
如果将上面配置文件中的路径配置为如下的绝对路径:
1 | root=F:\\project\\ClassifyRPC\\ClassifyServer\\src\\main\\resources\\HanLP\\ |
经过测试可以验证,HanLP的配置文件和词典可以正常解析加载,没有问题!
3、 将路径配置为classpath:开头的
1 | root=classpath:/resources/HanLP/ |
结果还是报错:
1 | 2020-07-03 11:23:41.749 WARN 29840 --- [pool-1-thread-1] HanLP : 读取classpath:/resources/HanLP/data/dictionary/CoreNatureDictionary.txt.bin时发生异常java.io.FileNotFoundException: classpath:\resources\HanLP\data\dictionary\CoreNatureDictionary.txt.bin (文件名、目录名或卷标语法不正确。) |
4、原因探究
4.1 hanlp源码读取root路径的逻辑:
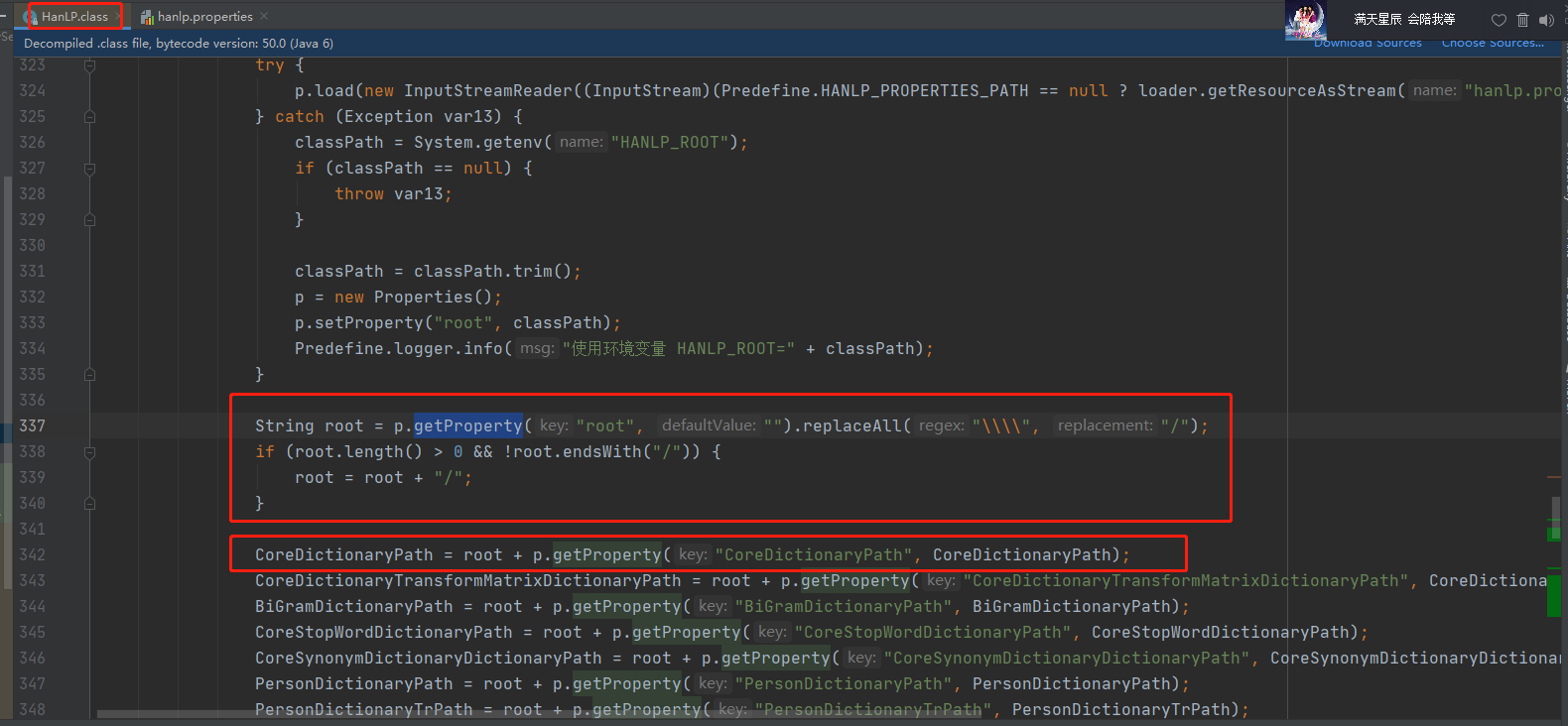
在HanLP.class源码中,我们看到根目录root就是直接读取我们配置文件中的路径,并且兼容windows文件系统路径,字典等路径就是根据这个root路径进行拼装,比如我们配置root为src/main/resources/HanLP/,则后续路径都是以src/main/resources/HanLP/开头的,读取失败应该是因为代码中没有取到这个相对路径的文件;
4.2 文件加载逻辑
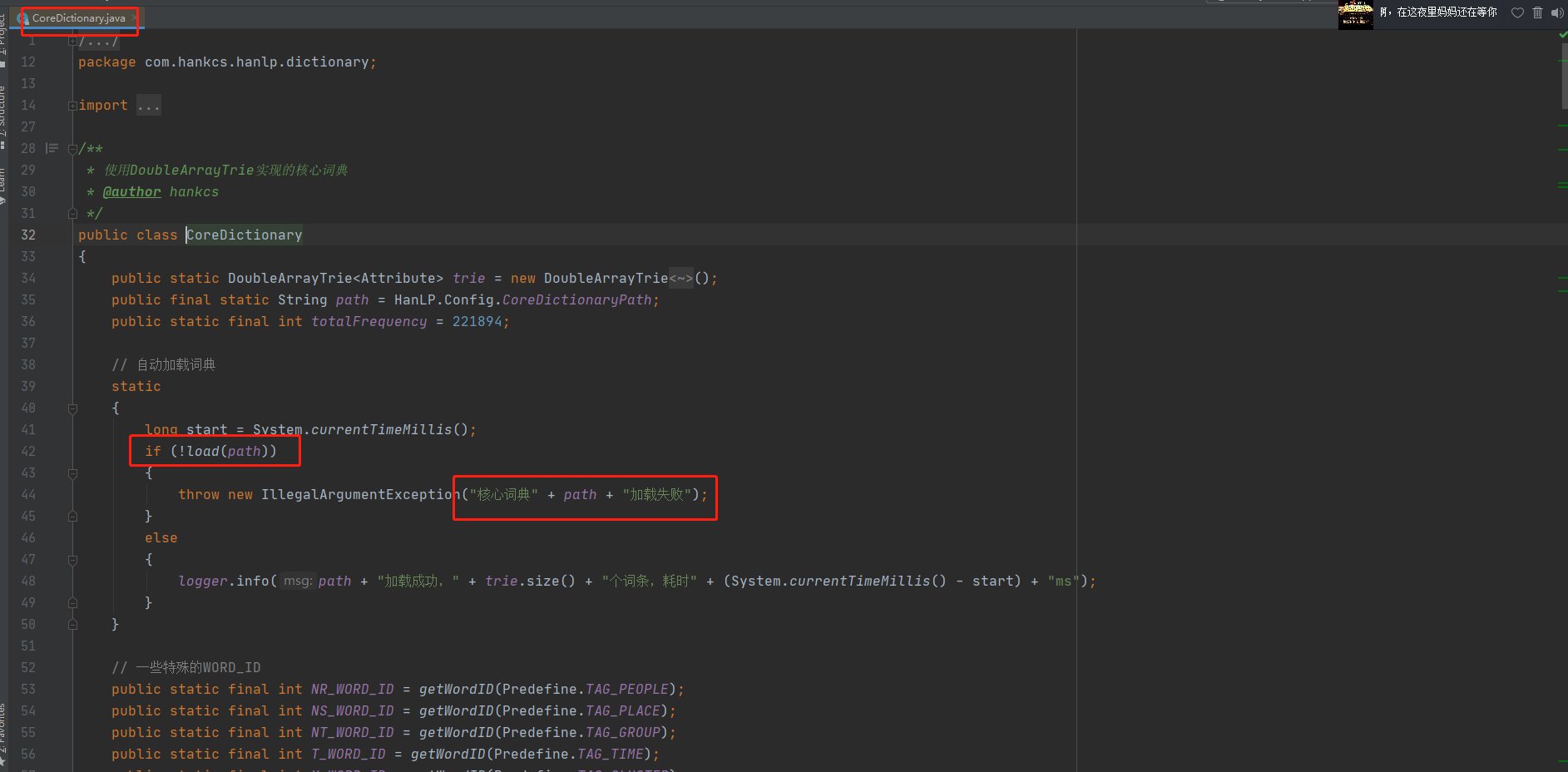
在CoreDictionary.java中的42行进行了词典的加载,这里出错,从而导致了上述错误;
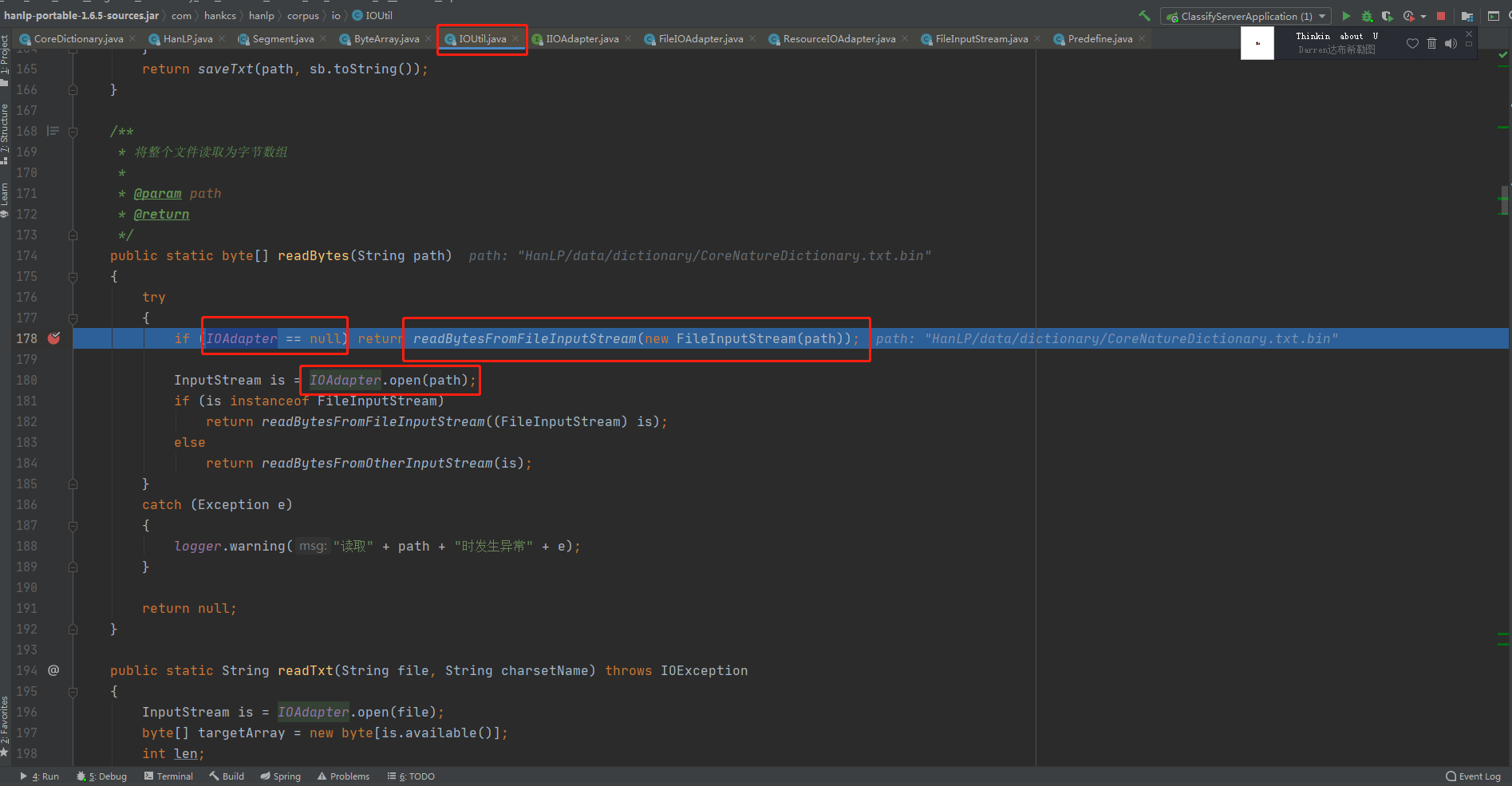
继续向下追踪,在IOUtil.java中,首先判断了IOAdapter是否为null,如果为null,则调用系统的FileInputStream,其中调用了new File()操作,对于相对路径的文件,确实会打开失败!
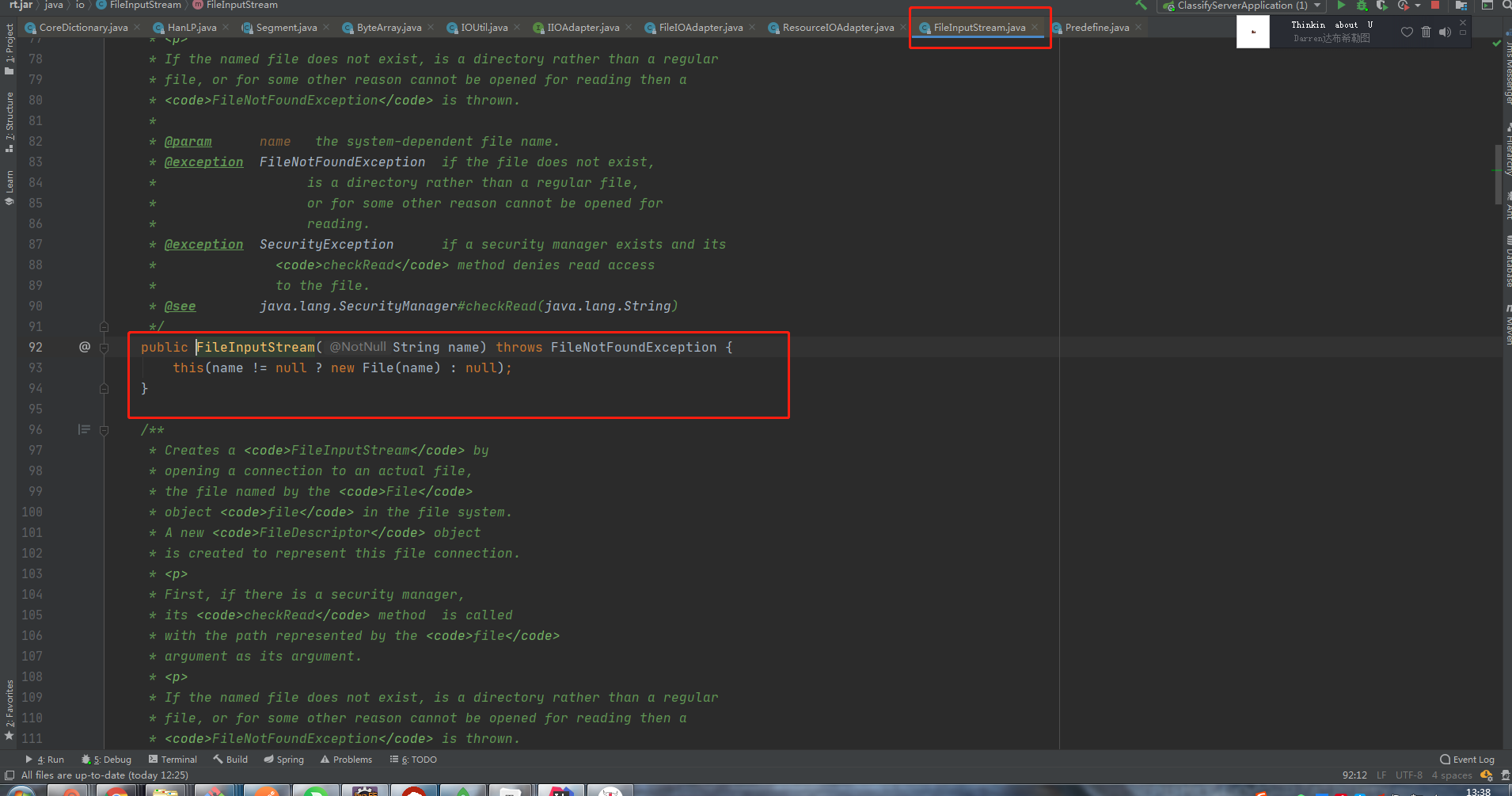
那么如果IOAdapter不为null的话,会调用IOAdapter.open(path),IOAdapter的实现类ResourceIOAdapter中的open函数如下所示:
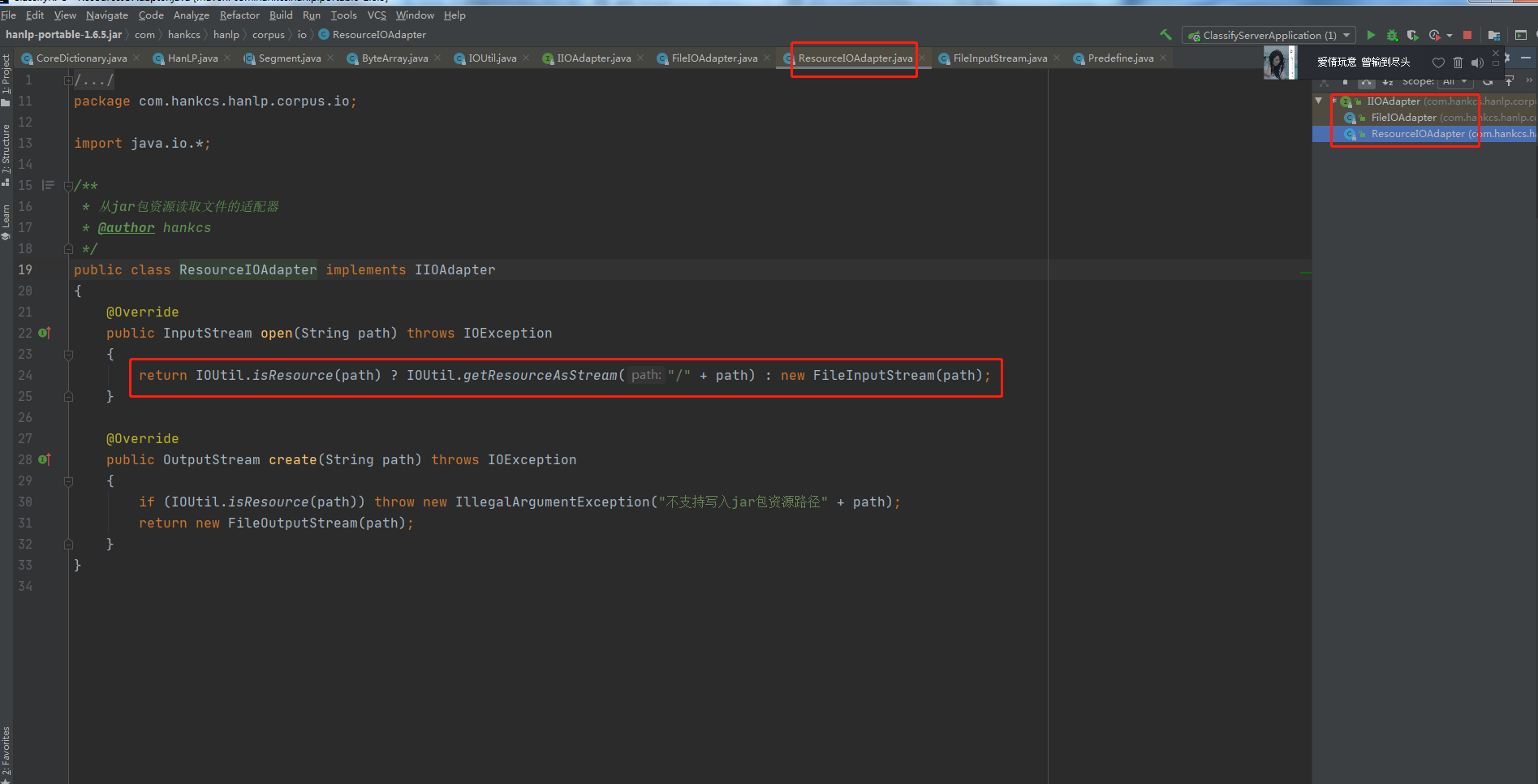
由上面代码可以看到这时就会去Resource中去寻找配置文件,我们尝试将IOAdapter激活,使其不为null;
4.3 激活IOAdapter
4.3.1 IIOAdapter适配器接口及示例
IOAdapter其实是接口IIOAdapter的一个实例,其中IIOAdapter接口默认有两个实现,分别是FileIOAdapter和ResourceIOAdapter;
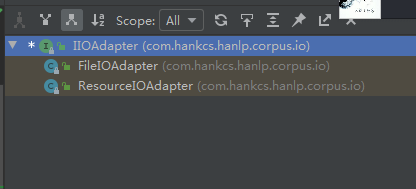
其中FileIOAdapter的代码逻辑如下,他是基于普通文件系统进行处理的:
1 | /* |
ResourceIOAdapter听上去特别像我们需要的文件处理适配器,具体代码如下:
1 | /* |
很明显,ResourceIOAdapter是为了处理从jar包资源读取文件的适配器;
4.3.2 自己定制IIOAdapter适配器
既然现有的适配器都不能满足我们的需要,那么我们就自己定制一个适配器,代码如下:
1 | package com.ict.mcg.config; |
在代码中加入上述适配器类,我们就不需要指定hanlp词典等绝对路径了,只需要将HanLP.data放到项目的resource下,并指定IOAdapter实例的类别,就可以愉快的开发了!
具体配置如下:
1 | root=HanLP/ |